PDF-Generatoren die aus einem HTML-Template ein PDF erzeugen, haben notorischerweise folgende Probleme die sich erst dann bemerkbar machen, wenn sehr große PDF-Dateien (über 100 Seiten) mit großen Inhalten erzeugt werden sollen.
- Das Rendern des HTML-Templates lädt alle Daten in den Heap-Speicher
- Das Erzeugen der PDF-Datei lädt alle Daten in den Heap-Speicher
in beiden Fällen kann dies zu einer OOM (Out Of Memory Exception) führen, welche die JVM und das Programm zum Absturz bringen kann, wenn das JVM-Heap Limit überschritten wird, da während der PDF-Generierung dieser allokierte Speicher nicht freigegeben werden kann, da er für die Generierung benötigt wird.
Um dies zu lösen, kann folgender Ansatz in vielen Fällen aufgehen:
- Es gilt zu prüfen, ob das HTML-Template in einzelne Sektionen unterteilt werden kann, die jeweils auf einer frischen PDF-Seite gerendert werden können.
- dadurch wird immer nur eine Sektion in den Speicher geladen
- Es gilt zu prüfen, ob bei der PDF-Generierung ein Streamin-Ansatz genutzt werden kann und ob auch hier die Sektionen jeweils separat an den PDF-Generator übergeben werden können, so dass dieser im Streaming-Approach jeweils nur eine Sektion in den Stream schreibt bzw. in memory lädt.
Ich würde diesen Ansatz mit folgenden Libraries/Frameworks aufzeigen:
- Quarkus (Backend)
- FlyingSaucer (PDF-Renderer)
- Qute (Quarkus HTML Template Rendering)
Wir haben ein Qute-Template welches eine gegeben Liste an Products in einer Loop rendert:
<!DOCTYPE html>
<html>
<body>
{#for product in products}
{product.productId}: {product.typeId} <br/>
{/for}
</body>
</html>Wir definieren dieses Qute-Template wie üblich für typsicheren Zugriff in Java:
package org.fk.product.template;
import io.quarkus.qute.TemplateInstance;
import io.quarkus.qute.CheckedTemplate;
import org.fk.product.dto.ProductDTO;
import java.util.List;
@CheckedTemplate
public class Templates {
public static native TemplateInstance productsTemplate(List<ProductDTO> products);
}
Nun definieren wir eine Quarkus REST Resource für den Zugriff auf die PDF-Generierung. Diese REST-Resource bekommt einen Parameter für die Größe der Chunk-Size übergeben.
package org.fk.product.controller.exports.pdf;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.StreamingOutput;
import org.apache.commons.lang3.RandomStringUtils;
import org.fk.core.exception.InvalidDataException;
import org.fk.core.request.RequestContext;
import org.fk.database1.Database1;
import org.fk.product.dto.ProductDTO;
import org.fk.product.manager.ProductManager;
import org.fk.product.template.Templates;
import org.jooq.DSLContext;
import org.xhtmlrenderer.pdf.ITextRenderer;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
@Path("/api/v1/exports/pdf/products")
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class ProductPdfExportControllerV1 {
@Inject
ProductManager productManager;
@Inject
Database1 database1;
@GET
@Produces(MediaType.APPLICATION_OCTET_STREAM)
@Path("/{chunkSize}")
public Response streamRootPdfInChunksFile(int chunkSize) throws InvalidDataException {
DSLContext dsl = database1.dsl(new RequestContext(1, 1));
var productStream = productManager.streamAll(dsl);
Stream<List<ProductDTO>> chunkStream = chunk(productStream, chunkSize);
StreamingOutput streamingOutput = outputStream -> {
Iterator<List<ProductDTO>> it = chunkStream.iterator();
ITextRenderer renderer = new ITextRenderer();
// we need to create the target PDF
// we'll create one page per input string, but we call layout for the first
String introductionPage = "<html>" +
" Introduction..." +
"</html>";
renderer.setDocumentFromString(introductionPage);
renderer.layout();
renderer.createPDF(outputStream, false);
// each page after the first we add using layout() followed by writeNextDocument()
while (it.hasNext()) {
List<ProductDTO> productsChunk = it.next();
List<ProductDTO> productsChunkWithData = productsChunk.stream().map(x -> x.setTypeId(generateLorem())).toList();
String html = Templates.productsTemplate(productsChunkWithData).render();
renderer.setDocumentFromString(html);
renderer.layout();
renderer.writeNextDocument();
}
// complete the PDF
renderer.finishPDF();
};
return Response
.ok(streamingOutput, MediaType.APPLICATION_OCTET_STREAM)
.header("Content-Disposition", "attachment; filename=product_export.pdf")
.build();
}
private String generateLorem() {
String generatedString = RandomStringUtils.randomAlphanumeric(50000);
return generatedString;
}
/**
* Helper function to chunk a stream of items into a stream of List of items.
*
* @param stream stream
* @param size chunk-size of each chunk
* @return stream of list of items.
*/
Stream<List<ProductDTO>> chunk(Stream<ProductDTO> stream, int size) {
Iterator<ProductDTO> iterator = stream.iterator();
Iterator<List<ProductDTO>> listIterator = new Iterator<>() {
public boolean hasNext() {
return iterator.hasNext();
}
public List<ProductDTO> next() {
List<ProductDTO> result = new ArrayList<>(size);
for (int i = 0; i < size && iterator.hasNext(); i++) {
result.add(iterator.next());
}
return result;
}
};
return StreamSupport.stream(((Iterable<List<ProductDTO>>) () -> listIterator).spliterator(), false);
}
}
Folgende Punkte hier kurz zusammengefasst:
- Es wird eine Menge an ca. 16000 Datensätzen (Products) aus der Datenbank mit Hilfe von “Streaming” abgeholt. Hierzu wird wie üblich JDBC-Streaming genutzt, so dass die Datenbank immer nur einen Rutsch an Datensätzen zurückliefert und nicht alle auf einmal.
- Der abgeholte Datensatz-Stream wird so umgewandelt, dass er immer einen Chunk an Products enthält, welcher der übergebenem Chunk-Size entspricht (z.b. 250 Products in einem Chunk).
- Es wird mit Quarkus ein Response generiert der einen StreamingOutput über REST zurückgibt. Das heißt, dass auch das Ausliefern der Daten über die Leitung streaming umgesetzt ist, so dass auch hier nicht alles auf einmal in den Speicher geladen wird, sondern schrittweise ausgeliefert wird.
- Es wird mit FlyingSaucer ein PDF in den OutputStream generiert.
- es wird zuerst eine Introduction-Seite generiert und mit “setDocumentFromString” direkt in den OutputStream ausgegegeben
- danach wird der Datensatz-Stream konsumiert und für jeden Chunk an 250 Products wird mit Hilfe von Qute ein HTML-Template gerendert, welches diese 250 Products rendert. Dadurch ist die Größe des HTML-Templates fix begrenzt und limitiert somit den verbrauchten Heap-Speicher auf diese 250 Items.
- Das so generierte HTML-Template für jeden dieser Chunks auch wieder via “setDocumentFromString” direkt in den OutputStream ausgegeben.
Es wurde mit Hilfe von VisualVM geprüft wie sich nun die Heap-Auslastung jeweils verhält.
Wenn wir die Chunk-Size auf 50000 setzen:
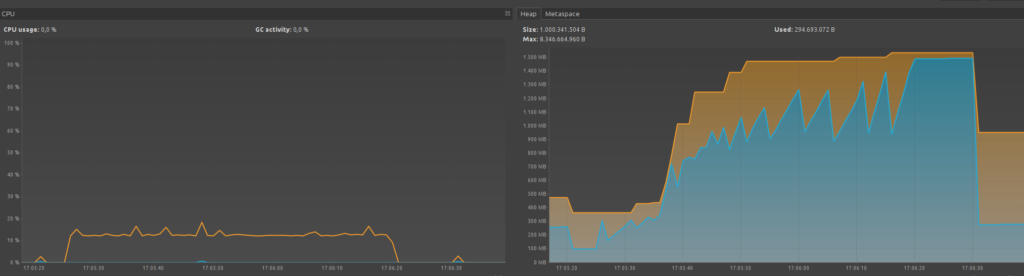
- Der Heap-Speicher steigt quasi unbegrenzt an und kann potentiell eine OutOfMemory-Exception verursachen wenn das Limit erreicht wird.
- ein Ausführen des Garbage-Collectors hilft nicht. Der Heap-Speicher kann nicht freigeräumt werden weil er während der kompletten Ausführung benötigt wird.
Wenn wir die Chunk-Size auf 250 setzen:
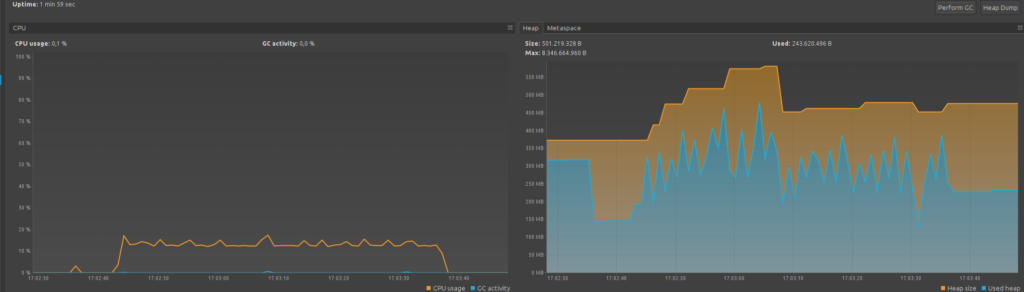
- Die Auslastung des Heap-Speichers bewegt sich in einem einschätzbaren Fenster und steigt nicht unbegrenzt an
- ein Ausführen des Garbage-Collectors hilft um alte bereits verarbeitete Chunks (250) freiräumen zu lassen, da diese nach Abarbeiten eines Chunks nicht mehr allokiert sein müssen.